MALT-2 is a distributed data-parallel machine learning system for Torch and MiLDE.
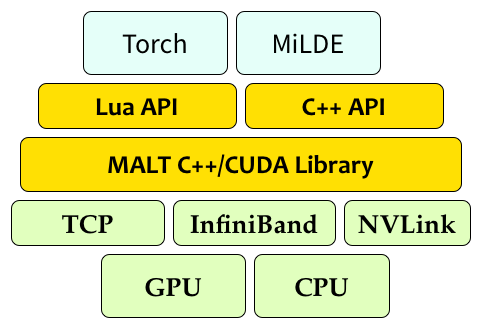
MALT-2 is a ML parallelization framework to paralleize any existing ML application. The system is designed to be simple to use and easy to extend, while maintaining efficiency and state-of-the-art accuracy.
- Easy to add to existing code general-purpose interface, requires only changing optimization type to dstsgd (distributed SGD).
- Support for multi-machine, multi-GPU training with CUDA implementations for distributed parameter averaging.
- Includes C++ and Lua interface to extend existing code. Support for Torch and NEC MiLDE (not open-sourced). Support for pytorch and darknet coming soon.
- Easily extend your existing Torch code with minimal changes.
- Explore existing distributed GPU apps over Resnets, and large language models.
- Various optimizations such as sparse-reduce, NOTIFY_ACK to accelerate distributed model training.
- Contributions Welcome!